How browsers render your website

Introduction
Since the early 2000s, and with the spread of the use of the Internet, the use of browsers has been increasing continuously. We can say now that Web browsers are probably the most widely used software. To understand how the browser is rendering the web resources we have to understand how the browser is actually working. In this series of articles, I will explain how they work behind the scene.
Definition of web browser
A browser is a software application that is used to present web resources by requesting them from the server by the URI (Uniform Resource Identifier) provided by the user in the address bar.
The browser's main components
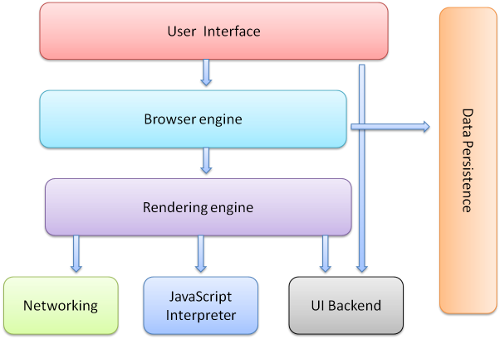
Figure 1: Reference architecture for web browsers
So as you see we have 7 main components you will find in any browser. let's dive in and see what actually are they.
The user interface - this is what the user sees, including the address bar, back/forward button, bookmarking menu, etc. Every part of the browser display except the window where you see the requested page. the browser's user interface is not specified in any formal specification, it is just good practices shaped over years of experience and by browsers imitating each other.
The browser engine - the heart of a browser, it marshals actions between the UI and the rendering engine. to understand it better, when the user hit the URL, it helps to present the content of the requested website.
- The rendering engine - is responsible for displaying requested content. For example, if the requested content is HTML, the rendering engine parses HTML and CSS and displays the parsed content on the screen.
- Networking - The protocol provides an URL and manages all sorts of safety, privacy and communication. In addition, the store network traffic gets saved in retrieved documents.
- UI backend - This component uses the user interface methods of the underlying operating system. It is mainly used for drawing basic widgets (windows and combo boxes).
- JavaScript interpreter - As you understand the name, it is responsible for parsing and executing the JavaScript code embedded in a website. Once the interpreted results are generated, they are forwarded to the rendering engine for displaying on the user interface.
- Data storage - It is a persistent layer. A web browser needs to store various types of data locally, for example, cookies. As a result, browsers must be compatible with data storage mechanisms such as WebSQL, IndexedDB, FileSystem, etc.
In Both firefox and chrome, the communication between components uses special communication infrastructures.
It is important also to note that Chrome, unlike most browsers, holds multiple instances of the rendering engine - one for each tab. Each tab is a separate process.
Some people are getting confused by the rendering engine and the browser engine but it's so simple. A browser engine comprises of 2 more engines:
- rendering engine.
- Javascript engine.
these 2 engines help the browser engine to represent the website you see on your screen.
The rendering engine
let's say that the user has requested a specific URL. the result will be a document whether it's HTML, PDF, or whatever, it's still a document, and here comes the role of the rendering engine. the rendering engine starts fetching the content of the requested document. This is done via the networking layer. The rendering engine starts receiving the content of that specific document in chunks of 8 KBs from the networking layer. After this, the basic flow of the rendering engine begins.

The rendering engine will start parsing the HTML document and turn the tags like
(<p></p>) to DOM nodes in a tree called the "content tree". It will parse the style data, both in external CSS files and in style elements. The styling information together with visual instructions in the HTML will be used to create another tree - the render tree.
So what's the render tree? The render tree is the combination of DOM and CSSOM. In order to create Render Tree, the browser starts traversing the DOM and looks for the matching styles in CSSOM, then these two are combined to create a render tree node that contains both content and style information. you can consider it as it is the visual representation of the document. The purpose of this tree is to enable painting the contents in their correct order.
The render tree contains rectangles with visual attributes like color and dimensions. The rectangles are in the right order to be displayed on the screen.
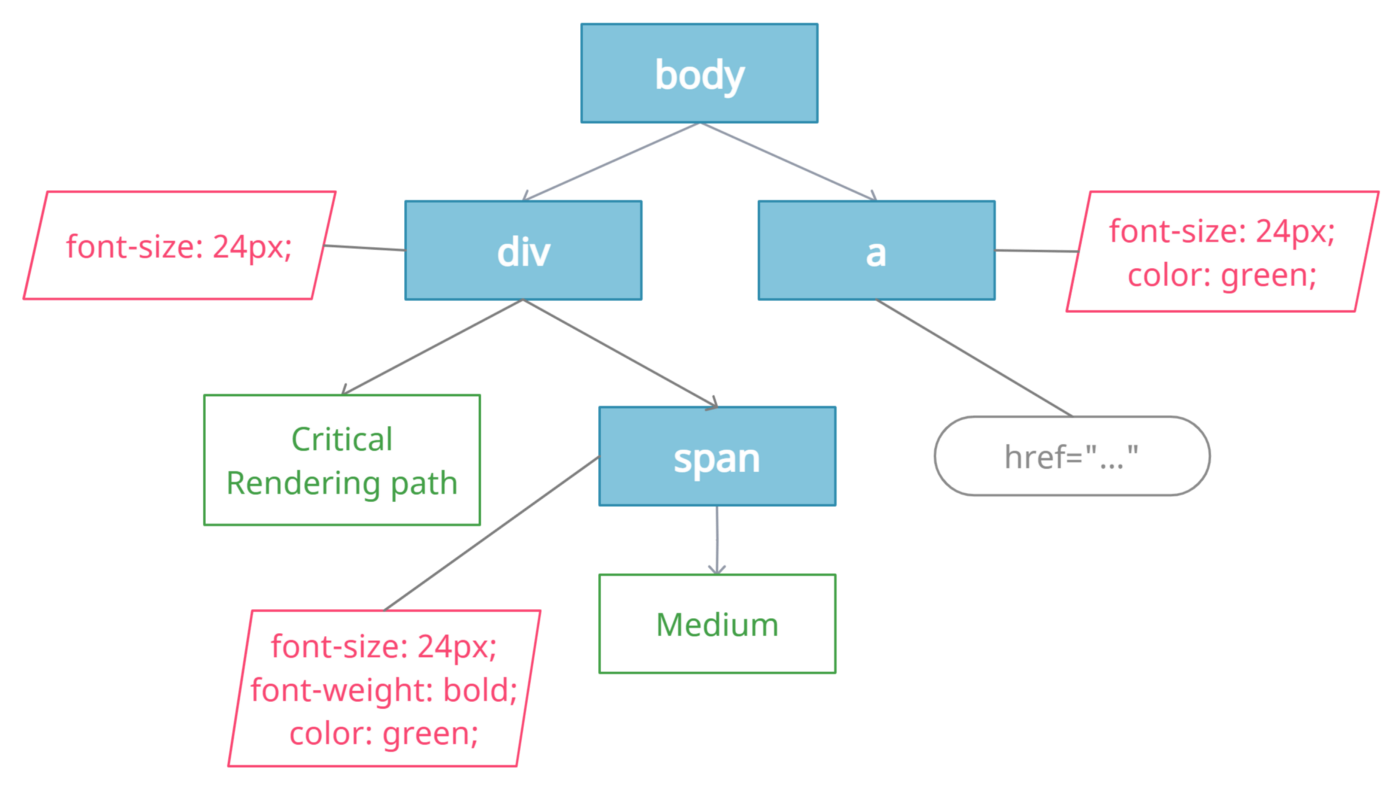 Figure 2: render tree example
Figure 2: render tree example
so what's next after the construction of the render tree? Here comes the Layout process. After the construction of the render tree, it goes through the layout process. This means giving each node the exact coordinates where it should appear on the screen. The next stage is painting - the render tree will be traversed and each node will be painted using the UI backend layer.
It's important to understand that this is a gradual process. For a better user experience, the rendering engine will try to display contents on the screen as soon as possible. It will not wait until all HTML is parsed before starting to build and layout the render tree. Parts of the content will be parsed and displayed, while the process continues with the rest of the contents that keeps coming from the network.
Main flow examples
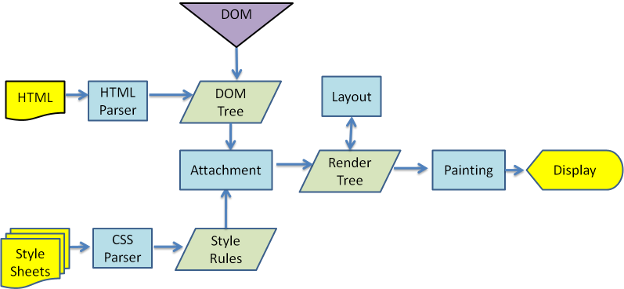 Figure 3: Webkit main flow
Figure 3: Webkit main flow
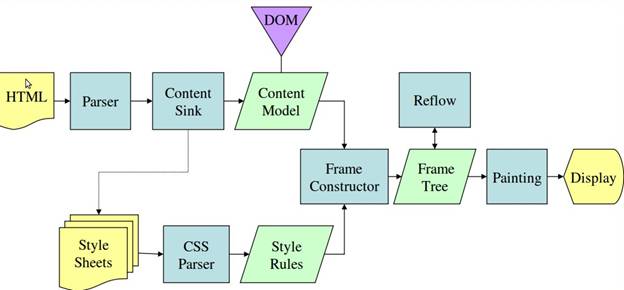 Figure 4: Mozilla's Gecko rendering engine main flow
Figure 4: Mozilla's Gecko rendering engine main flow
From Figures 3 and 4 you can notice the difference. they are using slightly different terminology but the main flow is basically the same. so what is the difference between these two flows?
- WebKit uses the term "layout" for the placing elements, while gecko calls it "Reflow"
- Gecko calls the tree of visually formatted elements - Frame tree. Each element is a frame. Webkit uses the term "Render Tree" and it consists of "Render Objects".
Webkit uses the term "layout" for the placing of elements, while Gecko calls it "Reflow".
A minor non-semantic difference is that Gecko has an extra layer between the HTML and the DOM tree. It is called the "content sink" and is a factory for making DOM elements.
conclusion
At the end of this article, we have come through the definition of web browser software. We discussed the main flow of any browser and the difference between browser engine and rendering engine. We also got an introduction to the rendering engine and some main flow examples. in the next articles, we will continue the parsing, layout, rendering, and painting.
This is my first article so I'm open to any feedback. Hope you like my article and enjoy reading it.
Resources
- Browser architecture 1.1 Grosskurth, Alan. A Reference Architecture for Web Browsers. http://grosskurth.ca/papers/browser-refarch.pdf.
- Webkit 2.1 David Hyatt, An Overview of WebCore. http://weblogs.mozillazine.org/hyatt/WebCore/chapter2.html. 2.2 David Hyatt, An Overview of WebCore. http://weblogs.mozillazine.org/hyatt/WebCore/chapter2.html.
- http://taligarsiel.com/Projects/howbrowserswork1.htm
